2.4. ОБЕСПЕЧЕНИЕ ОРГАНИЗАЦИИ И КОНТРОЛЯ ИСПОЛНЕНИЯ
КОНСТРУКТОРСКИХ РАБОТ
Введение
Наверх
Изложенный в п.2.1.1. материал рассматривает планирование работ без автоматической обратной связи, обеспечивающей повседневный контроль за состоянием работ и управления ими.
Наличие в системе управления информационных потоков, реализующих такой контроль, является строго необходимым, однако для каждого конкретного случая их структура различна. Здесь мы рассмотрим информационные потоки, обеспечивающие организацию, поддержку и контроль исполнения, отражающие специфику конструкторских работ. Аналогичное рассмотрение организации других работ будет проведено далее.
Итак, для конструкторских работ входной информацией является план работы каждого конкретного конструкторского бюро (КБ), выделенный из общего плана, сформированного на этапе, описанном в п.2.3.1. Однако, несмотря на то, что план задан в терминах классификатора ЕСКД, а у конструктора должно быть техническое задание на вариант конкретной реализации запланированного изделия, собственно конструирование начинать нельзя до тех пор, пока не будет проведён поиск аналогов в составе предыдущих и текущих разработок НПФ, с целью как унификации составных частей проектируемого изделия, так и повышения серийности изготовления за счёт увеличения количества однотипных изделий.
Решением здесь является организация информационного обмена между конструктором и ЭВМ, во время которого конструктор под управлением ЭВМ формирует в терминах классификатора ЕСКД описание детали (сборки, узла) и получает список номеров законченных и разрешённых к заимствованию изделий, который необходимо просмотреть (для исключения повторяемости) в альбомах систематизации. Первичный контроль возлагается при этом на руководителя работ, после чего исполнитель получает номер для разрабатываемого изделия и приступает к работе.
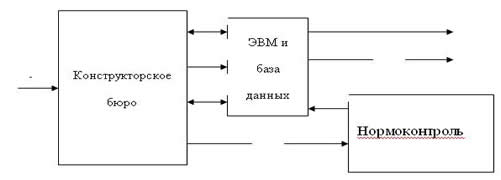 Рис 2.3. Информационный обмен между конструктором и ЭВМ.
Рис 2.3. Информационный обмен между конструктором и ЭВМ.
А – конкретный план работ, выделенный для данного КБ из общего плана.
В – работа с классификатором ЕСКД.
С – фиксация в ЭВМ начала работы по дате получения номера по классификатору ЕСКД.
Д – работа со списками МПИ.
Е – документы на традиционных носителях.
И – сведения о прохождении нормоконтроля.
К – оценка степени заимствования узлов и деталей.
Н – оценка готовности изделий по текущей готовности схемы состава изделия.
При этом в ЭВМ по дате выдачи номера по классификатору ЕСКД фиксируется дата начала работ над каждым конкретным изделием, т.е. реализуется указанная выше необходимость повседневного контроля. Учитывая, что приём нормоконтролёром документации является закрытием работ по конкретному номеру, что также фиксируется датой в ЭВМ, контроль процесса разработки становится серьезной организующей силой. Предметом производственных совещаний становятся не обсуждение данного разработчиком процента готовности, а оценка готовности изделия как результат сравнения плановой схемы состава изделия и её фактической текущей реализации, полученной от ЭВМ. Тем самым реализуется не только контроль как таковой, но и возможность своевременного выявления намечающихся задержек исполнения конструкторских работ.
Информационные потоки, имеющие место в описываемой ситуации, представлены на рис. 2.3 и сопровождены необходимыми пояснениями.
Так как основным конструкторским документом является спецификация, содержащая в себе все необходимые сведения для организации интересующих нас информационных потоков во взаимосвязи с учетной информацией классификатора ЕСКД, то ее разработка с использованием ЭВМ является обязательной задачей комплекса. Учитывая, что спецификация объединяет в себе сведения ряда документов, рассмотрим их создание и взаимосвязь в следующем разделе.
2.4.1. Обеспечение организации работы конструктора по составлению текстовых документов
Наверх
Из большого круга задач, стоящих перед конструктором при создании текстовых документов, нас непосредственно будут интересовать информационные потоки, обеспечивающие его работу с классификатором ЕСКД, перечнями элементов (ПЭ), спецификациями, ведомостями покупных изделий (ВП) и работа по проведению изменений в указанных документах. Для получения начальных сведений об этих документах необходимо обратиться к ГОСТ.
Итак, конструктор приступил к созданию спецификации, номер которой по классификатору ЕСКД сформирован в соответствии с п.2.3.2. Эта работа должна проходить под синтаксическим и семантическим контролем ЭВМ с исключением ручного ввода в ЭВМ самоочевидных вещей, типа наименования разделов спецификации. Ясно, что для обеспечения семантического контроля первых разделов в ЭВМ необходимо хранить все сведения о ранее разработанных спецификациях и деталях, для проверки по факту существования правомочности из включения в разрабатываемую спецификацию.
При переходе к разделу “Стандартные изделия” необходимо помнить, что первый вариант ПЭ (при его наличии) разрабатывается не конструктором, а лабараторией, дающей этому конструкторору задание. Для исключения дублирования работ по записи элементов, установим порядок. При котором лаборатория с помощью ЭВМ самостоятельно формирует и получает для схемы, спецификации и ПЭ номер по классификатору ЕСКД. Конструктор получает ПЭ, уже включённым в состав спецификации в разделы “Стандартные изделия” и “Прочие изделия”. Тогда эти разделы будут требовать только корректировки списка комплектующих элементов по результатам конструирования, а окончательный вариант ПЭ будет формироваться из спецификации автоматически.
Раздел “Материалы” конструктор формирует самостоятельно исходя из разрешённых типов записей. Информационные потоки, обеспечивающие процесс работы с МПИ, о которых уже упоминалось в 2.3.1, будут рассмотрены в 2.3.4.
Опуская на данном этапе рассмотрения тонкости, связанные с созданием различных допустимых видов спецификаций, а также последних разделов спецификаций, которые могут являться самостоятельными документами, рассмотрим информационные потоки, связанные с проведением изменений в документах, хранимых в ЭВМ и формируемых из них.
Движение информации здесь начинается (рис. 2.4.) с создания извещения об изменении – документа, рассчитанного на последующий труд чертёжника по внесению изменений в подлинник.
В случае формирования документов с использованием ЭВМ фактическим, хотя и не утверждённым подлинником, является машинная запись, существующая и хранимая одновременно с традиционным носителем. При этом порядок прохождения извещения на изменение несколько меняется, обеспечивая изменение прежде всего машинной записи. В принципе, хранящиеся в ЭВМ документы не доступны для внесения в них изменений. При наличии же извещения об изменении они должны становиться доступными инициатору извещения для внесения в них изменений, перевыпуска измененного и проверенного нормоконтролем документа и вновь закрываться для каких-либо коррекции. Соответственно, формируемые из спецификаций документа - ПЭ, ВП и другие должна перевыпускаться автоматически или по запросу.
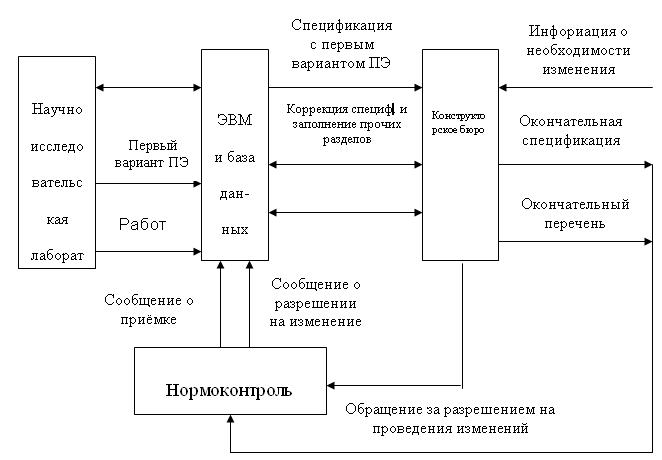
Рис. 2.4. Движение информации при составлении текстовых документов.
Извещение об изменении обычно содержит в себе графу «входимость», где должны быть перечислены все изделия, компоненты которых оно затрагивает. Следование классификатору ЕСКД принципиально ведет к обезличиванию документов, т.е. к их самостоятельному существованию вне какого-либо проекта. Исходя из этого будем полагать, что в НПФ налажен режим заимствования и коррекции узлов и деталей, соответствующий сути классификатора ЕСКД и трудоемкая работа по анализу входимости изменяемого документа (кроме специальных случаев) является излишней, хотя принципиально такая возможность не исключается.
2.4.2. Анализ текстовой конструкторской информации
Наверх
Современное производственное объединение для своей повседневной работы обязано располагать большими массивами нормативно – справочной информации. С первых попыток анализа и выбора такой информации с помощью вычислительной техники возник вопрос о её кодировании.
В первую очередь кодирование нужно для снятия семантической неоднозначности, легко решаемой человеком и недоступной для восприятия ЭВМ. Желание уменьшить необходимые размеры памяти ЭВМ для хранения информации и убыстрить поиск привело в общем случае к символьному кодированию и реляционным – иерархическим классификаторам с выделением принятых в семантике понятий классов, подклассов и т.п.
Для сокращения объёма памяти, занимаемой данными, используются разнообразные методы кодирования. Эти методы пригодны для хранения любой информации, но они дают наибольший эффект при хранении архивных файлов с невысокой частотой использования. Методы кодирования можно разделить на два класса:
1) Методы, ориентированные на конкретную структуру данных.
2)Универсальные методы.
К методам, ориентированным на конкретный тип данных, можно отнести следующие: исключение избыточных элементов данных, переход от естественных обозначений к более компактным, кодированным; подавление повторяющихся символов; ликвидация пустых мест в файле; кодирование часто повторяющихся элементов данных; сжатие упорядоченных данных.
К другим, универсальным методам относятся, прежде всего, посимвольное кодирование и кодирование кодами переменой длины (например, кодами Хаффмана).
При этом для сокращения потребляемой памяти ЭВМ могут быть предложены весьма эффективные методы внутреннего кодирования, о существовании которых потребитель может ничего и не знать.
2.4.3. Представление информации о материалах и покупных изделиях
Наверх
Любая система, в том числе и АСУ, должна иметь средства представления знаний (информации) о внешнем мире.
Для функционирования АСУ необходимо, прежде всего, информация о материалах и покупных изделиях (МПИ). Эта информация является базовой для системы, она должна быть заложена до начала промышленной эксплуатации АСУ. Знания должны быть описаны на некотором языке. Наиболее мощной известной системой хранения знаний является естественный язык, который я и буду использовать для представления знаний о МПИ.
Естественный язык обладает двумя основными функциями:
- Обозначение единичных объектов, а также средство для обозначения классов таких объектов.
- Отношение между объектами.
Теперь перейдём к рассмотрению информации о МПИ. Прежде всего, – это наименование МПИ, записанные в соответствии со стандартом.
Кодировать имена стандартного обозначения МПИ не имеет никакого смысла, ибо они, будучи стандартами, и так являются кодами объектов. Следовательно, если удастся снять неоднозначность, связанную с употреблением пробелов, отдельных символов и тому подобных ситуаций, затруднительных при интерпретации в ЭВМ, а также исключить ручной набор достаточно длинных текстов имён, то будет решена проблема бескодового употребления имён объектов, как человеком, так и ЭВМ.
Для каждого наименования может существовать сопутствующая информация, определяющая характеристики данного МПИ. Эта информация может состоять из дополнительных сведений о МПИ, не входящих в наименование (например: геометрические размеры, эксплуатационные данные, сведения о наличии МПИ на складе и т.д.).
С точки зрения пользователя язык представления знания (ЯПЗ) представляет собой модель собеседника, в результате диалога с которой он получает информацию (в данном случае о МПИ).
Описываемая система представления знаний о МПИ рассчитана как на студента, так и на конструктора, технолога, работника отдела стандартов или отдела снабжения, т.е. на тех людей, которые постоянно в процессе своей деятельности работают с наименованиями МПИ и сопутствующей им информацией.
В оптимальном варианте, при наличии достаточного объёма сопутствующей информации, предлагаемая система заменит справочники стандартов и обеспечит быстрый доступ в оперативном режиме через терминал любому пользователю по всему объёму информации о МПИ, накопленному на предприятии.
Грамматика языка представления знаний об МПИ
Прежде всего, рассмотрим грамматику наименований. Наименования состоят их нескольких слов естественного языка, и является предложением в терминологии грамматики.
Например, наименование:
Резистор ММТ – 1 1Ом ±20% ОЖО.468.086 ТУ (1)
можно разбить на следующие слова:
Резистор; ММТ –1; 1; Ом; ±20%; ОЖО.468.086 ТУ.
Такое расчленение определяется самим стандартом на запись наименования, т.к. в наименовании существуют определённые смысловые части.
Для (1) это соответственно: название наименования МПИ, его тип, мощность рассеяния, номинальное сопротивление, допуск и номер технического условия.
Поскольку в стандарте перечислены все допустимые наименования МПИ, то язык представления наименования можно считать контекстно-свободным с простейшей грамматикой, заданной перечнем всех допустимых предложений. Приведём фрагмент этого перечня:
Резистор ММТ – 1 1Ом ±10% ОЖО.468.086 ТУ
Резистор ММТ – 1 1.5Ом ±10% ОЖО.468.086 ТУ
Резистор ММТ – 1 1Ом ±20% ОЖО.468.086 ТУ
Резистор ММТ – 1 1.5Ом ±20% ОЖО.468.086 ТУ (2)
Резистор ММТ – 1 1кОм ±10% ОЖО.468.086 ТУ
Резистор ММТ – 1 1.5кОм ±10% ОЖО.468.086 ТУ
Резистор ММТ – 1 1кОм ±20% ОЖО.468.086 ТУ
Резистор ММТ – 1 1.5кОм ±20% ОЖО.468.086 ТУ
Из (2) видно, что грамматику можно представить в древовидном, табличном и др. видах. Если грамматику представить в виде дерева, то порядок слов будет определять уровень иерархии (см. 3).
1 2 3 4 5 6 - уровни иерархии
Резистор ММТ – 1 1 Ом ±10% ОЖО.468.086 ТУ
±20% ОЖО.468.086 ТУ
кОм ±10% ОЖО.468.086 ТУ
±20% ОЖО.468.086 ТУ (3)
1.5 Ом ±10% ОЖО.468.086 ТУ
±20% ОЖО.468.086 ТУ
кОм ±10% ОЖО.468.086 ТУ
±20% ОЖО.468.086 ТУ
Из (3) видно, что древовидное представление грамматики резко уменьшает объём памяти, необходимой для хранения информации на жёстком диске. В терминологии деревьев любой путь из корня дерева к терминальной вершине даст полное наименование МПИ.
Помимо описанных достоинств, древовидная грамматика обладает и рядом серьёзных недостатков. Например, из (3) видно, что хранить на нижних уровнях номер стандарта нецелесообразно, т.к. он одинаков для резисторов ММТ. Также нецелесообразно хранить и символы «-», «±», «%», которые повторяются для всех слов одного уровня.
Избыточность представления недопустима, т.к. число наименований МПИ исчисляется сотнями тысяч, так что возникает задача экономии памяти ЭВМ. Помимо этого, не следует забывать, что наименования должны быть введены в ЭВМ, а ввод столь большого их количества может занять очень много времени.
Ещё один серьёзный недостаток – поиск наименований путём пословной детализации только в порядке следования слов в наименовании. Для наименования из (2) это несущественно, но если взять наименование материала
Полоса 4?45 ГОСТ 4405-75 \ У10А ГОСТ 1435-74, (4)
в нём наиболее важным для конструктора является слово «У10А», определяющее марку материала. Т.к. это слово стоит далеко от начала наименования, пользователю придётся перебрать несколько менее существенных слов наименования, прежде чем он дойдёт до интересующей его марки материала.
Если грамматику представить в табличном виде, то порядок слов будет определять графы таблицы (см. табл. 2.3).
Таблица 2.3
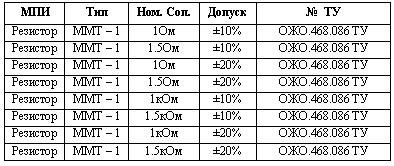
В таблице первой строкой располагаются имена атрибутов, и в последующих строках значения этих атрибутов. Множество пар {имя атрибута, значение} называются кортежами (из понятий реляционной модели данных). Предположим, что каждая запись содержит специальное поле, которое называется ключом. И потребуем, чтобы N ключей (множества из N записей) были различны, так что каждый ключ однозначно определяет свою запись. Совокупность всех записей называется таблицей или файлом, причём под таблицей, как правило, подразумевают небольшой файл, а файлом обычно называют большую таблицу. Большой файл, или группа файлов, часто называются базой данных.
Из таблице видно, что табличное представление грамматики не уменьшает объём памяти, необходимой для хранения информации по сравнению с иерархической грамматикой. Подобная сводка, содержащая все данные в одной строке (т.е. в одной записи), конечно же, далека от применения в качестве модели данных для конкретной задачи. Отдельные виды информации, такие, как МПИ, многократно повторяются в различных строках. Поэтому данное представление информации весьма избыточно. К тому же это представление обладает преимущественно теми же недостатками, что и древовидная. Но здесь есть одно преимущество – отсутствует поиск наименований путём пословной детализации в порядке следования слов в наименовании, что облегчает поиск таких наименований как показано в (4), когда ключевое слово находится не вначале наименования МПИ, а в середине или в конце.
Если грамматику представить в древовидно-табличном виде (см. табл. 2.4), то порядок слов будет определять сначала уровень иерархии, а потом графы таблицы.
Таблица_2.4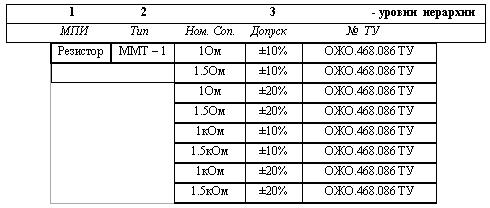
Из таблицы видно, что древовидно-табличное представление грамматики частично уменьшает объём памяти, необходимой для хранения информации на жёстком диске. Это представление обладает достоинствами и недостатками присущими как древовидной, так и табличной форм представления записей.
Какой же из этих видов представления информации в памяти ЭВМ целесообразней реализовать? Несмотря на указанные недостатки присущие древовидно-табличному представлению данных, всё же оптимальный выбор структуры МПИ падает на эту модель т.к. она содержит все необходимые, оптимальные методы и свойства по работе с данными такого типа.
2.4.4. Информационные потоки в ЭВМ, формируемые по запросу
Наверх
Кроме описанных выше информационных потоков, обеспечивающих сведения от первичных источников – планов, основных конструкторских и технологических документов, нормативно-справочной информации и т.п., в ЭВМ могут существовать и разовые, вторичные потоки. Речь идёт о получении информации по запросу, как обобщения или перекомпоновки некоторых сведений из первичных документов.
В принципе, в комплексе целесообразно иметь в наличии программы, обеспечивающие по запросу генерацию произвольных выходных форм. В общем случае эта работа достаточно сложна. Поэтому здесь рассмотрим только получение двух наиболее распространенных документов – ведомость покупных изделий (ВП) и ведомость материалов (ВМ).
Для ВП достаточной информацией является полный набор спецификаций изделия. Тогда для любой составляющей изделия или всего его может быть получена схема состава, а по ней – полный текст ВП с необходимыми количественными характеристиками. Высокая скорость формирования ВП позволяет создать её не заранее, а в момент необходимости, т.е. с учётом всех прошедших извещений на изменения.
Для ВМ достаточной информацией является полный набор спецификаций изделия и МТК. Тогда для любой составляющей изделия или всего его может быть получена схема состава, а по ней полный список ВМ с необходимыми количественными характеристиками и в сортаменте. Аналогично ВП, ВМ целесообразно создавать только при необходимости, а не заранее. Ясно, что при этом все прошедшие в спецификациях и маршрутных технологических картах изменения окажутся автоматически учтены в сводном документе.
К началу